Die Diskussion über digitale Geschäftsmodelle dreht sich häufig um Daten – „das Öl des 21. Jahrhunderts.“ Doch sind Daten nicht gleich Daten. Der folgende Beitrag differenziert verschiedene Typen von Kundendaten und zeigt für Unternehmen vom Mittelständer bis zur Großbank, wie diese im Wettbewerb um die Datenhoheit mit Google & Co. bestehen können. Kurz: ein Mehr an Daten ist nicht immer möglich oder nötig.
Daten sind nicht gleich Daten
Mehr als eine Million Treffer spuckt Google aus, wenn man gleichzeitig nach den Begriffen Daten und Geschäftsmodell sucht. Datengetriebene Geschäftsmodelle, bei denen Unternehmen aus den Daten ihrer Kunden Erkenntnisse generieren, um Produkte, Dienstleistungen oder die vertriebliche Ansprache zu optimieren, sind offenkundlich auf dem Vormarsch. Ein Beispiel dafür ist Google selbst: Das Kerngeschäft des Konzerns, der gerade erst sein zwanzigstes Firmenjubiläum feierte, ist die Sammlung, Verarbeitung und Nutzung von Daten – vor allem für intelligente Werbung. Mehr als 800 Milliarden Dollar ist die Google-Mutter Alphabet heute wert – fast so viel wie die größten 10 oder die kleinsten 25 DAX-Unternehmen zusammen.
Kaum noch eine Branche, die sich dem Trend nach mehr und mehr Daten entziehen kann oder will. „Die Datenanalyse rückt immer mehr in die Mitte unseres Geschäftsmodells“, so Commerzbank-Vorstandsvorsitzender Martin Zielke. Was der Bankchef sagt, könnte mittlerweile auch aus dem Munde eines Industriekapitäns aus der Automobil- oder Chemiebranche stammen.
„Daten und datengetriebene Geschäftsmodelle sind die Zukunft.“ „Daten sind das Öl des 21. Jahrhunderts.“ „Daten sind das unsichtbare Gold der Digitalisierung.“ So oft wiederholt, dass derartige Sätze schon zur Binsenweisheit verkommen sind, klammern sie eine wichtige Erkenntnis aus: Daten sind nicht gleich Daten. Weder in den Augen der Kunden, noch in ihrem Wert für die Unternehmen.
Die Datenhackordnung der Kundendaten – vom Herausposaunten bis zum Höchstpersönlichen
Auch wenn der Eindruck in Zeiten von Selbstvermarktung in sozialen Netzwerken manchmal anders sein mag – Kunden achten durchaus auf den Schutz der eigenen Daten. Sie differenzieren dabei aber stark nach deren Sensibilität. Grob lassen sich personenbezogene Daten aus Kundensicht in drei Kategorien einteilen, wie Abb. 1 darstellt.
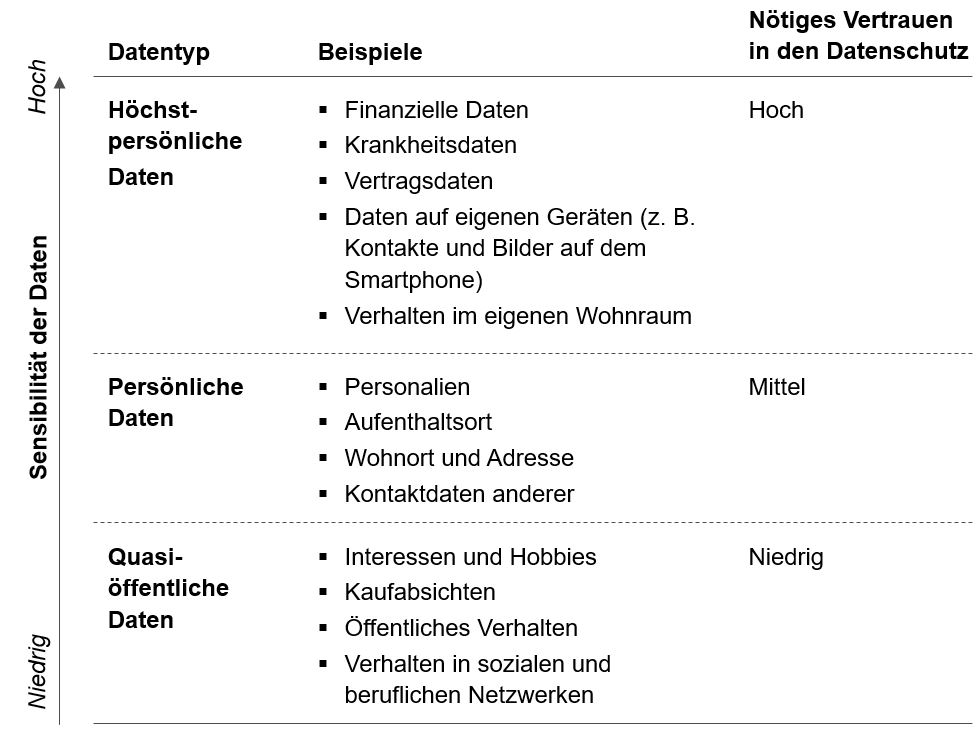
- Quasi-öffentliche Daten: Diese entstammen Handlungen der Kunden, die sie entweder bewusst öffentlich tätigen oder bei denen sie in Kauf nehmen, dass die Daten ohne nennenswerte Barrieren einer größeren Öffentlichkeit zugänglich sind. Dazu gehören ein Profil in sozialen Netzwerken oder Online-Aktivitäten wie das Kommentieren oder gar Schreiben von Blogbeiträgen. Auch akzeptieren viele Kunden, dass ihre im Internet geäußerten Kaufabsichten (z. B. Suche eines bestimmten Produktes) verwendet werden (z. B. für gezielte Werbung).
- Persönliche Daten: Hierzu gehören Angaben zur Person (Wohnort, Alter) ebenso wie Kontaktdaten auf dem Smartphone, die Kunden nicht ohne Erlaubnis zur Verwendung an Dritte weitergeben möchten. Sie schützen diese Daten vor dem Zugriff Dritter, sind aber bereit, sie bei Bedarf bereitzustellen, sollten ihnen daraus Vorteile entstehen (etwa Komfortgewinn bei der Anmeldung für Online-Dienste oder für die Nutzung von gratis Chat-Diensten wie WhatsApp).
- Höchstpersönliche Daten: Sie unterscheiden sich von persönlichen Daten durch ein besonders hohes Maß an Vertraulichkeit. Hierunter fallen alle Informationen, die ein Kunde – digital oder analog – nicht jenseits seiner unmittelbaren Privatsphäre geteilt sehen möchte, wie etwa Krankheits- (denn Gesundheitsdaten, wie die zuletzt gelaufene Joggingrunde nebst Pulsprofil, werden bisweilen gerne geteilt) oder Finanzdaten.
Datenschutz ist Kunden unterschiedlich wichtig
Diese Hackordnung verschiedener Datentypen zeigt sich auch bei der Befragung der Kunden – wie Abb. 2 am Beispiel einer Befragung von Bankkunden darstellt. Kunden kategorisieren die eigenen Daten klar nach deren Sensibilität – von Dingen, die die Welt ruhig (auch ungefragt) wissen soll oder darf bis zu den Geheimnissen, die auf keinen Fall das Licht der Öffentlichkeit sehen dürfen. Dritten wollen sie diese persönlichen und höchstpersönlichen Daten nur zugänglich machen, wenn sie einen klaren Nutzen daraus ziehen – und wenn sie die Hoheit über die Daten behalten.

Trotz der Datenexplosion: Rinnsale statt sprudelnder Datenquellen
Diese Kundenhaltung trägt dazu bei, dass sich für Unternehmen ein Datenfluss-Paradox entwickelt: Die Flut der relevanten Daten steigt weiter dramatisch. Allein zwischen 2016 und 2025 soll sich das weltweit generierte Datenvolumen noch einmal verzehnfachen. Auf dann 163 Zettabyte – das Speichervolumen von einer Billion Blue Ray-Disks. Aufeinandergestapelt würden diese einen Turm bilden, der zweimal von der Erde zum Mond reicht. Pro Jahr!
Indes: Der Zugang zu diesen Daten wird für Unternehmen schwieriger. Zwar schwillt der Datenstrom, diesen anzuzapfen fällt aber zunehmend schwerer. Denn, wenigstens in Europa, greifen immer strengere datenschutzrechtliche Vorschriften, die empfindliche Strafen gegen widerrechtliche Datenerhebung und -nutzung vorsehen. Die Hektik um die Datenschutz-Grundverordnung (DSGVO) rund um deren Geltungsbeginn im Mai dieses Jahres verdeutlicht dies. Die Regelungen sollen die Rechte der Verbraucher an den eigenen Daten stärken. Unternehmen dürfen Daten nur noch bei klarem Zweckbezug und nach expliziter Erlaubnis durch den Kunden verwenden.
Kundendaten durch Mehrwerte als Kompensation für Vertrauen
Ebendiese Erlaubnis erteilen Verbraucher aber nicht unbesonnen, sondern einer klaren Überlegung folgend: Mehrwert für die Daten und Vertrauen in den Datennutzer müssen aus Kundensicht „passen“. Hier kommt die oben geschilderte Sensibilität der verschiedenen Datenarten ins Spiel, denn je Sensibilitätsstufe müssen die beiden Faktoren – also Mehrwert und Vertrauen – mehr oder minder groß sein. Dabei lässt sich beobachten, dass Mehrwerte das Grundvertrauen in die Anbieter zu einem gewissen Grade kompensieren können: Ist der Mehrwert groß genug, teilt der Kunde auch persönliche Daten, die ein mittleres Vertrauen in den Datenschutz voraussetzen, selbst wenn das Unternehmen, das um die Daten wirbt, nicht sein vollstes Vertrauen beim Thema Datenschutz genießt. Dabei gibt es aber Grenzen: Höchstpersönliche Daten können kaum durch unternehmensgenerierte Mehrwerte gewonnen werden, wenn das Vertrauen in das um sie bittende Unternehmen nicht hoch ist.

Wertversprechen allein reichen nicht aus, um an die persönlichen und höchstpersönlichen Daten zu gelangen. Vertrauen in den Datenschutz ist nur zu einem gewissen Teil durch Mehrwerte wettzumachen. Um Zugang auch zu den sensibelsten Daten zu erhalten, müssen einzelne Unternehmen daher ein möglichst hohes Maß an Vertrauen besitzen.
Vertrauen in Sicherheit von Kundendaten variiert nach Unternehmen
Das Vertrauen in verschiedenen Unternehmenstypen variiert allerdings stark (siehe Abb. 4): Kunden vertrauen bestimmten Institutionen, wie etwa Banken, Versicherungen, Krankenkassen oder dem Staat. Schon geringer ist das Vertrauen der Kunden in deutsche Industrieunternehmen oder Onlinehändler. Deutlich weniger vertrauen Kunden internationalen Großkonzernen oder sozialen Netzwerken – ebenjenen Informationskonzernen, die unter dem Akronym „GAFA“ (Google, Apple, Facebook, Amazon) als enorme Datensammler bekannt sind.
Nicht zufällig beruht die Attraktivität der „GAFAs“ im Wesentlichen auf gratis angebotenen Mehrwerten (Suche, Navigation, Kalender, Netzwerk, …). Denn diese Unternehmen sind sich bewusst, dass sie Mehrwerte bieten müssen, um ihre geringe Vertrauenswürdigkeit zu kompensieren. Ganz ohne Vertrauen geht es aber auch für sie nicht. Deshalb gibt es immer wieder Versuche, ihre Vertrauenswürdigkeit zu steigern, wie die neusten Kampagnen (z. B. von Facebook) oder Googles Motto „don’t be evil“ zeigen. Trotz dieser vertrauensbildenden Worte und trotz der performanten Gratis-Angebote, werden diese Unternehmen aber kaum an sensible Nutzerdaten kommen.
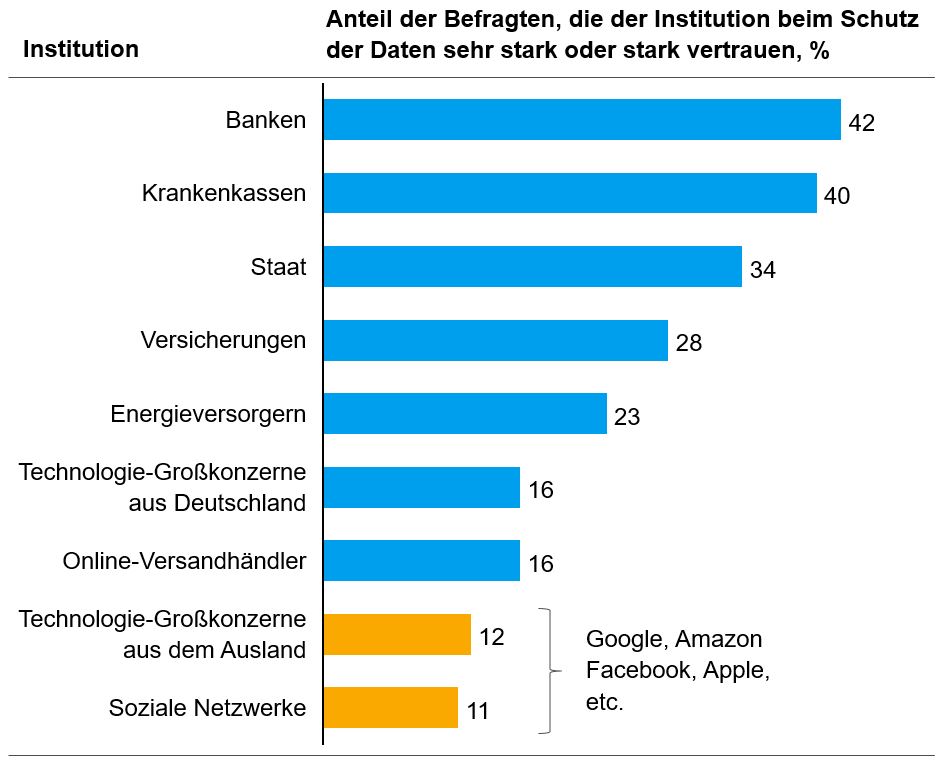
Auch für Unternehmen jenseits der GAFA-Gruppe gilt: Wenn sie nicht den Status „besonders vertrauenswürdig“ erlangen, müssen sie ihre Geschäfte auf die quasi-öffentlichen und weniger sensiblen persönlichen Daten aufbauen. Ganz wie Google & Co.
Informationskonzerne sammeln viele Daten, nutzen sie aber kaum
Letztere haben das Wechselspiel zwischen Vertrauen und Mehrwert verstanden und gleichzeitig die finanziellen Ressourcen, um kundenrelevante Mehrwerte anzubieten – aus denen sie wiederum Marktanteile und Erträge generieren, die ihnen das Angebot weiterer Mehrwerte ermöglichen. Allerdings schöpfen auch diese Unternehmen selten das volle Potential ihrer Kundendaten aus. Googles Erfolg basiert weitestgehend auf seiner Vormachtstellung als Suchmaschine – dem Torhüter der Informationen. Beispiele wie die doch eher grobschlächtigen Amazon-Produktempfehlungen („Andere Käufer dieses Artikels haben auch gekauft“) zeigen, dass Datenbesitz nicht gleich sinnvolle Datennutzung ist.
Auch kleine Unternehmen können den Kunden mit quasi-öffentlichen Informationen besser verstehen
Darüber hinaus mangelt es den Digitalkonzernen am persönlichen Kundenkontakt, der in vielen Branchen immer noch nötig ist, um Kundenwünsche zu verstehen (etwa im B2B-Bereich oder bei der Beratung im Laden). Diesen Kundenkontakt können kleinere Unternehmen, die mit quasi-öffentlichen Daten arbeiten, nicht nur nutzen, um zusätzliche, relevante Kenntnisse zu erlangen. Den Kundenkontakt sollten diese Unternehmen so mit Daten aufwerten, dass sie Wettbewerbsvorteile erzielen können, sei es über gezieltere Angebote oder über eine bessere Preissetzung.

Unternehmen müssen also nicht zwangsläufig so viele Daten wie Google oder Amazon sammeln. Wichtiger ist es, diejenigen Daten zu identifizieren, die dem Unternehmen helfen, seine relevanten Kunden besser zu verstehen. Darauf aufbauend können auch kleinere Unternehmen jenseits des „Circle of Trust“ ihr Angebot für den Kunden verbessern – und gleichzeitig hoffentlich die eigene Wertschöpfung erhöhen.
Unternehmen mit sensiblen Kundendaten können neue Geschäftsmodelle erschließen
Es gibt aber auch Unternehmen, die derzeit noch einen Vertrauensvorschuss genießen, der Kundendaten in diesem Bereich vor dem Zugriff der Informationskonzerne schützt. Wie oben erwähnt besitzen beispielsweise Krankenkassen oder Banken Informationen, die höchstpersönlich sind. Gleichzeitig vertrauen Kunden diesen Unternehmen, zumindest im Arbeitsbereich des Unternehmens (also Krankheitsdaten für eine Versicherung).
Analog zum vorherigen Beispiel sollten diese Unternehmen versuchen, ihr Geschäftsmodell auf Basis bestehender Kundendaten zu stärken (d. h. höhere Wertschöpfung für Kunden, mehr oder profitablere Umsätze). Einerseits um sich von den anderen Vertrauenswürdigen abzuheben. Andererseits um sich in Richtung der großen Informationskonzerne abzusichern.
Darüber hinaus können diese Unternehmen versuchen, neue Geschäftsmodelle zu erschließen, die auf denjenigen Daten beruhen, die Unternehmen schon besitzen, die Kunden aber nicht leichtfertig mit anderen teilen würden. Einige Erweiterungsmöglichkeiten seien hier beispielhaft erwähnt:
- Erweiterung entlang der Wertschöpfungskette (z. B. Zahlungsdienstleistungen, Vorfinanzierung von Erstattungen von Internethändlern)
- Erweiterung in angrenzende Bereiche (z. B. von bestehenden Verträgen und Empfehlung von besseren)
- Monetarisierung von Komfortfunktionen (z. B. Lösungen zum einfachen Austausch zwischen verschiedenen Unternehmen [sog. „Single Sign-on“]; Aggregation mehrerer Informationsquellen)
- Geschäftsmodelle, die originär auf Daten beruhen (z. B. Versicherung nach Verhalten)
Man sieht also, dass es Potential für neue Geschäftsfelder gibt. Diese Geschäftsfelder sind aber nicht einfach zu identifizieren und aufzubauen, auch da es teils schon Konkurrenzangebote gibt. Bei jeder Erweiterung des Geschäftsmodells ist außerdem ein behutsames Vorgehen nötig, da durch eine zu radikale Nutzung der Kundendaten das bestehende Vertrauen auch schnell verloren gehen kann.
Credo: Aus allen Kundendaten kann man etwas machen – man muss es nur wollen
Aus diesem Beitrag sollte klar werden, dass Fatalismus für die Nicht-GAFAs auch in Zeiten, in denen Daten das neue Öl sind, fehl am Platze ist. Zwar verfügen internationale Informationskonzerne über die meisten dieser Ölquellen. Diese können sie (a) aber, zumindest derzeit, noch nicht ausreichend nutzen und (b) nicht auf alle Geschäftsbereiche ausweiten. Unternehmen, die mit quasi-öffentlichen Daten arbeiten, sollten versuchen, als Bereichsspezialisten auf Basis der ihnen zur Verfügung stehenden Daten den Kunden besser zu verstehen und zu versorgen als die Generalisten Google oder Amazon. Bildlich gesprochen, reichen ihnen unter Umständen schon wenige Tropfen aus der eigenen, kleinen Ölquelle, um den Geschäftsmotor zum Laufen zu bringen. Unternehmen, die qua Vertrauen vom Kunden auch Zugang zu höchstpersönlichen Daten erhalten, genießen sogar noch eine Atempause vor der Konkurrenz durch die Informationskonzerne. Diese Pause sollten sie aber nicht auf der faulen Haut, sondern zur Erweiterung ihrer Geschäftsmodelle mit den ihnen noch exklusiv zur Verfügung stehenden Daten nutzen.
 Foto: BLC, 2018 |
Der Erstautor, Dr. Michael Seibold, arbeitet im Bereich Strategy & Corporate Development bei Volkswagen Financial Services. Zuvor war er Manager bei der Beratungsgesellschaft Berg Lund & Company (BLC) mit Beratungsschwerpunkt Großbanken, Regionalbanken, Börsen und Investmentgesellschaften. Sein besonderes Augenmerk gilt Fragen der Digitalisierung sowie Smart Data. |
Dieser Beitrag ist Teil einer Serie, die Praktiker als Gastautoren zu Wort kommen lässt (siehe vorheriger Beitrag zur Zukunft von Mobile Payment).